Improving Performance and SEO in One Go all for Single Page Application

The world of web programming is increasingly geared towards pages which contain only strictly necessary coding. What can we do to create complete, efficient and automatically indexable solutions on search engines and social networking sites?
Nowadays, every modern web app, as well as sites such as blogs and information sites, is developed as a single page application (SPA). Instead of traditional methods where users click on one link after another to open a new page, every user interaction causes the page to update its content.


browsing. This reduces the waiting time for new pages to a minimum.
In terms of development, an SPA consists of changing the “pageview logic” (that is to say the algorithms which regulate the visual content) from the server to the client. This relegates the former to the only task of providing strictly necessary information to give the complete web experience. This also means that the initial HTML frame of the page is completely stripped of all its content and looks something like this:
<!DOCTYPE html>
<html lang="it">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<link rel="manifest" href="/manifest.json">
<link rel="shortcut icon" href="/favicon.ico">
<title>La nostra vetrina</title>
</head>
<body>
<div id="root"></div>
<script src="/static/css/styles.js"<>/script>
<script src="/static/js/bundle.js"<>/script>
</body>
</html>
It is, without a doubt, very fast to download and interpret. However, in practical terms, this brings about some new challenges to overcome.
Problems with Search Engines
This SPA approach can easily be applied to web apps that don’t need to be indexed, as we have recently done to an event planning web app for private bankers. On the other hand, some problems occur for some websites that require search engine optimization.
Almost all websites in the world are explored and catalogued by various search engines from Google to Bing from Yandex to Baidu. This happens by using crawler bot: an application that allows you to analyse the webpage and automatically build a sitemap.
Being automatic tools means that they don’t need to recreate the graphical user interface to be able to operate, which is why to carry out their task they limit the amount of resources to load, such as style sheets or scripts.
In the past these bots completely excluded the loading and execution of style sheets and above all script for the functioning of the page, which limited them solely to the static analysis of HTML content. Therefore, when faced with an SPA, search engines wouldn’t show any content, making the site effectively empty even with the presence of a sitemap.
Today we know it is no longer like this, which is why even search engine bots download and carry out scripts necessary for the site to function. Does this mean that we can stop worrying? Unfortunately, the situation is that that simple.
CrawlerBased on Old Browser Engines
Bots often utilise basic browser search engines to recreate pages to analyse. However, there is no guarantee that these engines are aligned with versions that users of the site normally use. An example of this is the Google bot which in May 2018 was still based on Chrome 41 , but became obsolete in April 2015.
This means that our SPA might not function correctly on these browser engines, jeopardising the correct display of content. This is a problem which is often ignored especially because the automatic tests aren’t usually performed on platforms this old.
There aren’t only search engines
While search engines fulfil their purpose by cataloguing sites and in the years that have passed have therefore developed sophisticated algorithms for content extraction, it often happens that our pages are analysed and shown by other automatic tools.
The classic example of this is sharing a link on social networks like Facebook or Twitter, or on messaging applications such as Whatsapp or Telegram.
These apps have implemented the useful function of showing a site preview provided by the link, showing the title, main image and the beginning of the page’s content (retrieved through heuristic process or by simply using open graph tags), therefore increasing the user’s interest in discovering what more there is to see.
The problem of such preview functions is that they aren’t as sophisticated as search engine bots, so previews might not be generated or it might generate incorrectly.
Performance Problems
Another aspect to consider is the performance of our sites. In fact, when we are leisurely browsing on our PC, using the home or office network, we rarely encounter problems with resource loading times or unresponsive pages.
However, we find ourselves in a completely different situation when browsing the same site using an electronic device, which is often equipped with inferior data storage and power, even if sometimes the band width is not strong due to poor connection. This is a really big issue, given that it has already been some years since internet access via mobile platforms has overtaken desktop versions.
A common problem with SPAs is that all of the interface templates are managed by Javascript, like all view logic. It follows that, for the app to function large bundles are created by Javascript containing page management libraries, templates and logic. We are talking about dimensions of a few megabytes depending on the complexity of the application.
All this of this comes at a price in terms of processing and this translates into higher waiting times for the page to appear and the possibility to interact with the page.
This is an extremely delicate time, seeing as generally it’s suggested that a page becomes interactive in less than a second to avoid users losing their patience and leaving the page.
Server-Side Rendering
The solution to both of these types of problems is known as server-side rendering (SSR). The operation essentially consists of, and to tell the truth has always been known as, leaving the server to recreate the page’s HTML skeleton and sending the result to the client instead of the “outline” of the document shown above.
Generally speaking this is exactly what happened normally on multi-page sites before SPA came out, so at a glance it seems like we are returning to old systems! In reality, the problem is more complex.
The main difference is that the recreation of the page on the server happens only on the user’s first access to the site or web application, while the following phases of browsing proceed like a normal SPA. This has the following advantages:
- As a matter of fact search engines and sharing systems on social network pages behave like “a user’s first access to the page”. They will no longer find themselves
obliged to index simple drafts. Instead they will be able to count on the full content of the page. - Seeing as the page content is already available to the user from the first access to the site, it’s possible to delay loading creation scripts of the pageview and of the
manager of the page immediately after. This reduces the quantity of data to download before the user can see or interact with the page.

How SSR Comes About
In SPA, the scripting is responsible for creating the pageview of the page. The server could have been developed using different languages such as Java or PHP. In order to recreate the pageview to send to the client, the server should in some way mirror their behaviour: a laborious task which is subject to errors.
Consequently, the server architecture should be recalled in a way so that the page creation is the engine’s task which is able to perform Javascript in it, and because of this it should use a Node.js server to achieve this.
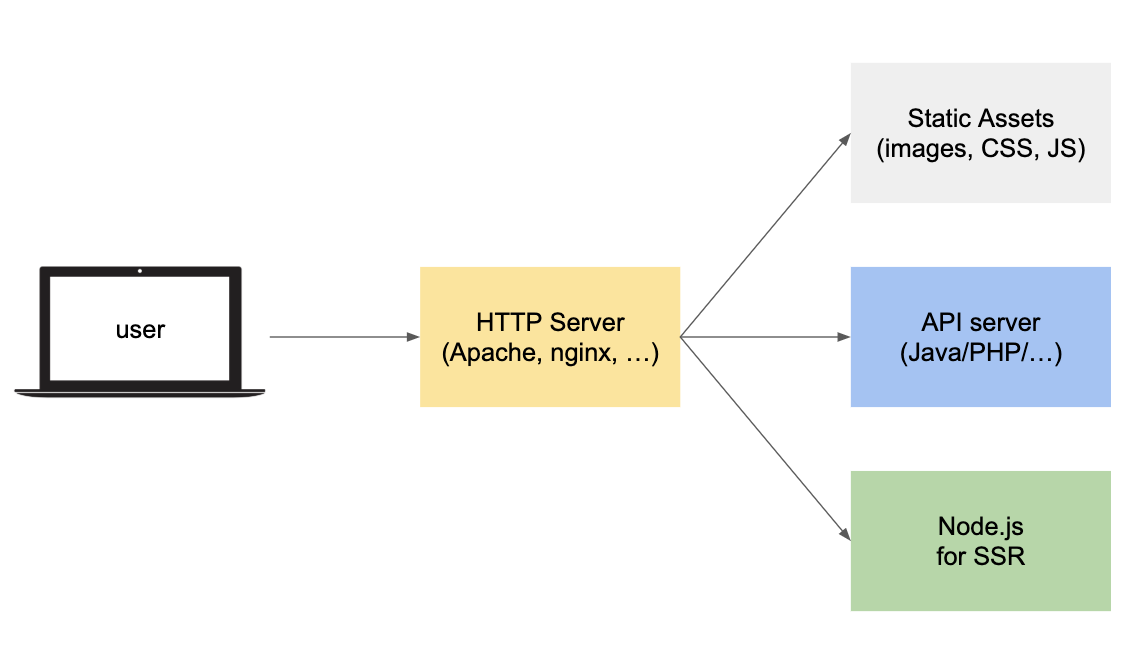
Imagining a very simple architecture, a HTTP server sorts requests carried out by the client to a CDN for statistic resources or to the server that displays API for web applications, and in all other cases to a Node.js server to create the pageview.
This system also has a secondary advantage which is that it can respond with an appropriate error code if incorrect requests are made (such as 404 or 401), or from the common status code 200 if the operation of the creation of the pageview is left to the client. This doesn’t normally impact the average user who is browsing the site, but it can make a difference for a bot in understanding if an address is actually valid or inaccessible.
On the Road to Optimization
There are many tricks that can be done to improve the performance of the application itself or website; in particular, lazy loading of resources that consists of loading images, fonts, media, style sheets or scripts only in the moment that the client actually makes the request.

The next step consists of initially limiting the management only to above-the-fold content (a term taken from printed paper which shows content that the user sees at the top of the page). In this step, the critical rendering path is separated from the rest of the application. With this, you can also do it in a way that some resources (such as style sheets and script) are sent inline on the page thanks, yet again, to server-side rendering.
This method can also reduce, even drastically, the size of statistic resources transferred to the user. Normal communication procedures with servers work in a way that when transferring data over 14.6kB there is an initial brief “congestion”, therefore the optimal objective consists of sending, within those limits, everything necessary for the first view of the page.
Advanced techniques require separate in-depth analysis, but the advantages would disappear without an adequate system of server-side rendering.
